The machine learning can be categorized into three types. They are:
- Supervised Learning,
- Unsupervised Learning and
- Reinforcement Learning.
The variation in machine learning is caused by variation in training method.
Supervised Learning
Supervised learning is similar to our learning process. That means the way we, humans, learn things and the way supervised learning works are similar. Think about the elementary mathematical problems. We know how to solve them, this is called knowledge. Using existing knowledge, we solve a problem and compare our solution with the correct solution. If it matches, we consider our solution as correct. If it does not match, we modify our approach and try again. The following steps of problem solving will help you understand better:
Step 1: Selecting a Problem
First of all, we select a problem to solve.
Step 2: Apply Solution
Then we use what we already know to solve the problem. This is called the knowledge.
Step 3: Compare Result
After solving the problem, we compare our result with the correct result.
Step 4: Decision Making
If the result matches with the correct result, we consider our knowledge as accurate. If the result does not match with correct result, we modify our knowledge and repeat step 2.
Let’s compare the above problem-solving strategy of human with machine learning. Here the exercise problem represents the training data in machine learning. And the knowledge we apply to solve problems represents the ‘model’ in machine learning. When the steps mentioned above used in machine learning it is called supervised leaning.
In supervised learning the training data unit is consisted of input and correct output. The input is the training data and the correct output is what the model should produce for that particular input. Mathematically, we express the data unit as: {input, correct output}.
Learning in supervised learning is like a series of revision of a model. In each revision, the difference between output and the correct output is reduced. When the difference between output and correct output becomes negligible, we call it properly trained. The less the difference the better accuracy of the training process.
Unsupervised Learning
Unsupervised learning is the machine learning algorithm where there is known known or labelled output and the algorithm learns from pattern analysis by inferring the correct output. It may sound strange that how come the algorithm works without knowing the correct output. Look at the following figure:
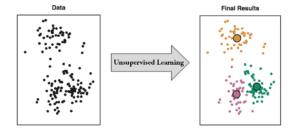
The data are in left-hand side. Observe the distribution of the data carefully. There is a pattern there. On the right-hand side, the pattern has been marked with circle. In unsupervised learning these types of patters are utilized to infer the possible correct output. Unsupervised learning is generally used for investigating the characteristics of data. When we investigate something, obviously the outcome is not known. If the outcome is known, then there is no need of any investigation.
An example will make the unsupervised learning clearer. Think of a murder case. There detectives do not know who is the killer. However, they investigate the crime scene and use the available clues to find out the killer. Here the clues are the data. And the relation between the clue and the killer is the pattern. In unsupervised learning, this pattern is used to find out the correct output.
Reinforcement Learning
The machine learning algorithm that automatically determines the ideal behaviour within a specific context to maximize the performance is called reinforcement learning. It is difficult to understand what reinforcement learning actually is from definition. The following illustration will make the concept clear.
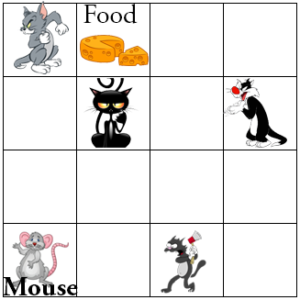
Here, the mouse wants the food. But it does not know the best way to get the food. There are four cats in four different location. The mouse will try different ways. When it faces a cat, it decides it as a wrong move. Eventually the mouse will be able to find the best way to get the food. Next time when the mouse will be hungry again, it will follow the same way to get the food. Here the mouse is the algorithm. The food is the reinforcement. And the best way is the solution.
The reinforcement learning algorithm keep searching for the best solution. When it finds the solution, it grades the way of finding the solution. If the algorithm finds 3 ways of solving a particular problem, it will grade the 3 ways as good, better and best. Next time, when the similar problem will be assigned, the algorithm will choose the best way to solve the problem.
In this book, the only the supervised learning has been covered. The application of supervised learning is much more than those of unsupervised and reinforcement learning. And the prominent reason of keeping the context within supervised learning is – this the first thing you should learn while entering the world of machine learning and deep learning.
Supervised learning is further divided into two categories. They are
- Classification and
- Regression.
Let’s learn a little more about classification and regression.
Classification
Classification is finding the classes to which the data belongs. For example, in spam mail filtering, the mails are classified in two classes – (1) regular mail and (2) spam mail. When the spam mail filtering system receives email, it assigns mails to appropriate classes. If an e-mail carries harmful content, then it is assigned to ‘spam’ class. Otherwise it is assigned to ‘regular’ class.
In supervised learning, the training data is paired as {input, correct output}. The training data in classification problem is paired as {input, class}. In supervised learning, we train models to find out the correct output. And in classification we train models to find out which class in data belong to.
The following table shows the comparison between training data and target of supervised learning and classification.
| Training Data | Target | |
| Supervised Leering | {input, correct output} | Finding the correct output |
| Classification | {input, class} | Assigning appropriate class |
Table 1.1: Training data and target of supervised learning and classification.
Regression
Regression is type of supervised learning where values are estimated instead of class or correct output. Take a look at the following dataset.
| Age (years) | Income (in USD) |
| 18 | $1,200 |
| 20 | $1,800 |
| 26 | $2,300 |
| 38 | $1,900 |
| 40 | $2,500 |
| 55 | $47,000 |
| 60 | $6,000 |
Here, a list of age and corresponding income at this age are presented. In regression approach, the model will learn from this relation and will predict the corresponding earning for a certain age.

In the figure above, the dataset of the {age, income} has been illustrated. Here the points on the curve, which have values mentioned ($1200, $1800 and so on) are training data. After training, the system can predict corresponding earning for a certain age.
The following table will help you understand the difference among supervised learning, classification and regression.
| Training Data | Target | |
| Supervised Leering | {input, correct output} | Finding the correct output |
| Classification | {input, class} | Assigning appropriate class |
| Regression | {input, corresponding value} | Finding an estimated value |
Note that, classification and regression are both parts of supervised learning. That is why the general format of training data is {input, correct output}. The difference is on the type of correct output. In classification, the correct output is class and in regression the correct output is corresponding value.
In supervised learning, when we need to group data in different groups, we used classification method. And when we need to estimate the trends of data, we use regression method.
Before wrapping up this chapter, I like to highlight a common confusion between classification and clustering. Clustering is a method used in unsupervised learning. It examines the characteristics of data and then categorizes the related data together. Although the results of classification and clustering are similar, they are completely two different approaches.



{kind=link}